Table of Contents

Aside from basic commands such as cd, ls, mkdir, touch, etc., there is a short list of commands that I think every bash user should know about and attempt to use on a regular basis.
- grep
- awk/sed
- less
- find and exec
- gunzip
- tar
grep
Grep is a tool that will find certain patterns or words in one or more files. It comes in two versions--BSD and GNU. Mac computers will come with the BSD version while linux computers will come with the GNU version. For our intent, these versions are identical, but if you ever run into issues cross-platform, be sure to check that the grep command you are executing is supported in your grep version (certain types of regular expressions not supported in BSD grep).
You can think of grep as the "search" tool built-in to the command line. In today's computing environments, there are plenty of search tools and in most cases, I would opt to use the search tools provided to me. For example, in the Visual Studio Code Editor, I can use the search bar to search through all the files in my project for a specific word or even regular expression, and I will get results listing the files that the expression was found in, what line it was found on, etc.
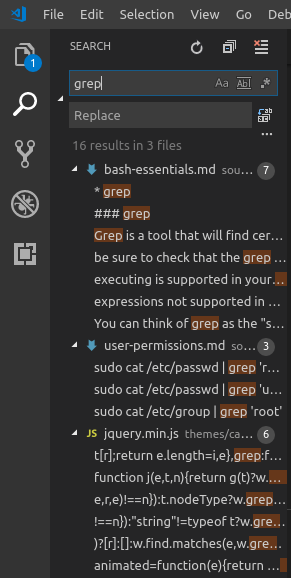
In this example, I was searching my entire blog for the word "grep" and found it in 3 separate files. But what if VSCode is not available to you? Maybe you are managing a remote machine and you simply cannot access this awesome search feature. In that case, you are going to need to use grep. The basic syntax for using grep is the following:
grep [all your options] "text to search for" <file-to-search-in>
For example, if I wanted to search the /etc/passwd file (where all the users on our system are stored) for my name, I could do it like so.
# Must use sudo because this file is protected
# The -i flag will make my search case insensitive
sudo grep -i "zach" /etc/passwd
# zach:x:1000:1000:Zach,,,:/home/zach:/bin/bash
Although this tutorial is not meant to cover regular expressions in detail, I could also search by a regular expression. Maybe I wanted to match any user that had a name equaling 3 characters. I would perform the following search while adding the -E flag for "extended regular expressions".
sudo grep --color -E "^[a-z]{3}:" /etc/passwd
# Output ---
#bin:x:2:2:bin:/bin:/usr/sbin/nologin
#sys:x:3:3:sys:/dev:/usr/sbin/nologin
#man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
#irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
#gdm:x:121:125:Gnome Display Manager:/var/lib/gdm3:/bin/false
bin, sys, man, irc, and gdm are all three-letter usernames. If your output does not print in color, you can add the --color flag to your command.
Another way to use grep is through piping. We can pip the stdout of one command to the stdin of grep. The same command we just wrote about can be modified and written like so:
sudo cat /etc/passwd | grep --color -E "^[a-z]{3}:"
Again, the grep utility is useful for quick searches when you do not have access to your normal text editor like VSCode.
awk and sed
Nowadays, awk and sed are contentious topics, and in this section, I hope to clarify why this is the case and introduce the two commands' basic usages. The reason these two commands are contested frequently is due to the better alternatives that we have today. Both of these tools are considered text editors because they can find and replace parts of a file or files.
Sed is a "stream editor" (looks at each line character by character) and is not considered a full programming language. It is great for little find-and-replace operations across one or more files. Again, I would recommend just using a built-in find/replace utility if it is available (like in VSCode), but sometimes this is not accessible.
Awk considered a computationally complete programming language and is catered more towards large data that is delimiter separated. For example, the awk tool would be good at parsing through a csv file, or a file separated by spaces because it reads each line in chunks rather than characters.
The reason these utilities are highly contentious is because anything you can do in sed or awk can be done in Perl or Python in a simpler manner. Perl and Python are far more advanced and usable scripting languages. Many will argue the superior performance of sed and awk in certain situations, but for all practical purposes, it is more often the case that Perl or Python will be the better solution.
Not to beat a dead horse here, but again, if you do not have access to Python or Perl (remember, you must download these to a machine while sed/awk are usually installed already), you are going to need to learn how to use sed and awk. Now the question becomes--what is the difference? Why would I use sed over awk or vice-versa? Here are few quick rules of thumb:
- For simple text transformations (like find/replace), use sed.
- For simple formatting transformations, use awk
- For complex formatting/text transformations, use awk
Let's take a look at an example of each and cover the basic usage of both tools. We will start with a simple find/replace operation with sed. For these examples, I will be using a sample file of Apple Inc. stock data over the last 3 months called aapl.csv. Here is the data:
Date,Open,High,Low,Close,Adj Close,Volume
2018-11-06,201.919998,204.720001,201.690002,203.770004,203.061493,31882900
2018-11-07,205.970001,210.059998,204.130005,209.949997,209.219986,33424400
2018-11-08,209.979996,210.119995,206.750000,208.490005,208.490005,25362600
... omitted for brevity ...
2019-02-04,167.410004,171.660004,167.279999,171.250000,171.250000,31495500
2019-02-05,172.860001,175.080002,172.350006,174.179993,174.179993,36066500
Say I wanted to replace all the commas with spaces instead. I could do this quickly with sed.
sed 's/,/ /g' AAPL.csv
Date Open High Low Close Adj Close Volume
2018-11-06 201.919998 204.720001 201.690002 203.770004 203.061493 31882900
2018-11-07 205.970001 210.059998 204.130005 209.949997 209.219986 33424400
2018-11-08 209.979996 210.119995 206.750000 208.490005 208.490005 25362600
... omitted for brevity ...
2019-02-04 167.410004 171.660004 167.279999 171.250000 171.250000 31495500
2019-02-05 172.860001 175.080002 172.350006 174.179993 174.179993 36066500
This will print the output of the sed transformation. If I add the -i flag to the command, it will edit the file.
sed -i 's/,/ /g' AAPL.csv
Now that we have the file separated by spaces, we can look to awk to do some better summarization. This data is a bit confusing in its current state because it has multiple versions of the stock price (open, high, low, close, adjusted). I just want to see the date, open, and volume. To get that, I can use awk.
awk -F " " ' BEGIN { print "Date\t\tPrice\t\tVolume" }; NR > 1 { print $1 "\t" $2 "\t" $7 } ' aapl.csv
Date Price Volume
2018-11-06 201.919998 31882900
2018-11-07 205.970001 33424400
2018-11-08 209.979996 25362600
... omitted for brevity ...
2019-02-04 167.410004 31495500
2019-02-05 172.860001 36066500
I know this command looks overly complex and difficult to learn and the purpose of this tutorial is not to make you an awk expert, but let's take a moment to walk through the basic syntax of an awk command. Once you know the basic syntax, a few Google searches will usually get you to the awk one-liner that you need for your given situation.
Awk is a bit of a tough command to learn because it is more of a programming language than a command line tool. To learn what the command above means, let's write it into a file for greater clarity. I have created a file called awk-example.sh and placed the above command in it with better formatting.
# This is an awk comment
# Before processing any text, we want to set the FS variable (what our file is separated by),
# the OFS variable (what our output is separated by), and then print a header for our output.
BEGIN {
# Notice how each line is ended with a semicolon -- similar to C programming language
FS=" ";
OFS="\t";
print "Date\t\tPrice\t\tVolume";
};
# NR > 1 means that we only want to print the following bracket enclosed values for lines that are greater
# than line 1. In other words, we are omitting the first line.
NR > 1 {
# We want to print the first, second, and seventh value in each line.
print $1, $2, $7;
};
We can run this file like so:
# Outputs the same thing as
# awk -F " " ' BEGIN { print "Date\t\tPrice\t\tVolume" }; NR > 1 { print $1 "\t" $2 "\t" $7 } ' aapl.csv
# This reads the awk-example.sh file and executes it against aapl.csv
awk -f awk-example.sh aapl.csv
As you might have noticed there are some built in variables to awk which include FS (file separator), OFS (output separator), NR (number of rows), and many more that can be found here. We can use these variables rather than the command line flags. For example, instead of writing -F " ", we can just set the FS variable in our awk file.
Learning awk entirely would take far more time than is warranted here in this tutorial, but if you can remember the basic syntax, you'll be good to go. Ultimately, each awk command is a series of keywords and outputs. The command we just ran is shown below in this format.
# awk executable Options Keyword What to print based on keyword Keyword What to print based on keyword file to run
awk -F " " ' BEGIN { print "Date\t\tPrice\t\tVolume" }; NR > 1 { print $1 "\t" $2 "\t" $7 } ' aapl.csv
Awk can do much more than what has been shown including editing files. A great introductory tutorial can be found here.
When push comes to shove, you generally do not need to be proficient in sed nor awk. Perl/Python can do the same exact things with simpler syntax. That said, knowing the basic usage of each can significantly speed up your workflow during those few moments where they do become necessary. They can also become useful when you are writing a bash script and need a built-in text editor. It would be inconvenient to break out of a bash script, run a python script, and then start your script again, so sed and awk provide nice alternatives to this workflow.
Less
Less is one of those command line utilities that you are probably not using and should be. I find myself scrolling through large output all the time and forget that there is a command line utility that makes this a lot easier. Less is simple to use, and works very similar to vim. You can run less in two ways:
# Pipe output into less
cat some-large-file.txt | less
# Use less directly
less some-large-file.txt
Once you are in less, your biggest asset is the h option. Type h and you will receive a help panel with all the possible commands you can run. I will go through some of the most useful and common.
- To scroll up a line, press
k(like vim) - To scroll down a line, press
j(like vim) - To go to end of file, press
G - To go to beginning of file, press
g - To search for "some text", type
/some text(to search forward) or `? - To go forward an entire window, type
for spacebar - To go back a window, press
b
Just like grep, awk, and sed, scrolling and searching through output can be done in advanced text editors like VSCode fairly easily and if you have the opportunity to use these more advanced tools, go ahead and do so. Using the less command is simply for those moments when those tools are not available to you.
find and exec
The find command is eerily similar to grep at first glance, but covers an entirely different use case. You would need to use the find command when you want to search for certain files within the entire filesystem. While grep searches for text in a file or a specified output, find searches explicitly for files in the filesystem. Why is this useful? Many times this command could be used to find the path where a specific executable is stored on the filesystem so you can edit, move, or remove it. Maybe you installed a version of Python a long time ago and cannot remember where you downloaded it. It is a common problem to have conflicting installations of Python on your machine. It is also common to struggle to entirely remove Python from your machine. Other uses for find could include:
- Find all of the .png files on your computer
- Find all documents modified by some user in the last 7 days
- Find any file that has a certain permission set
As you can see, the possibilities here are endless and if used to its potential, the find command can solve a lot of issues that you never knew it could. A quick example:
find / -type f -size +1G
This command will list all of the files on your computer that are greater than 1 Gigabyte in size. If you're low on disk space, this command will be your good friend and help you find those files that are taking up unecessary space on your computer.
The basic syntax for the find command is:
find <directory to search> [options] <file name to search>
Here are a few rapid-fire find commands to get you started.
# Finds all jpg files on your system
find / -type f "*.jpg"
# Finds all files modified in the last day
find / -type f -mtime 1
# Find all files that belong to zach
find / -type f -user zach
# Find all files with 777 permissions
find / -type f -perm 777
# Find all files that start with the word config
find / -type f -name "config*"
These are just a couple of the thousands of possibilities here. Furthermore, you can use the exec command to take the find command to a new level. Instead of just finding a bunch of files, you can perform operations on them. Although very powerful, this also can be very dangerous if you are not careful. The exec function will do as you might guess and execute a command on every single file that was found by find. So if you combine the find and rm command together using exec, you may delete a bunch of files. So before we get into it, be careful!
Here is a simple find command that will find all the jpg files in our home directory.
find ~/ -type f -name "*.jpg"
If we wanted to copy all the matches to a ~/pictures-backup folder, you can add the exec command.
find ~/ -type f -name "*.jpg" -exec cp '{}' ~/pictures-backup \;
You might be wondering what the '{}' and \; pieces of this command mean. If you use your new skills, you can find more information about the exec command by piping the find man pages into less and searching for the word "exec".
man find | less
/-exec
n # repeats the search for -exec and finds next occurrence of it
In these man pages, you can see that the '{}' is where the files that were found are placed in the command and \; is a character that tells the exec script to stop executing. The backslash is just a safety mechanism. You could also use ';'.
After running this command, you now have all the jpg pictures in your entire home directory copied to a centralized backup repository! You can begin to see how powerful this new command is!
tar, gzip, gunzip
These utilities are fairly simple and used to compress and decompress files. Many times when we download a software release or series of large files or images, we will get them in the .tar, .gz, or even .tar.gz formats. tar and gz are slightly different. tar is an archive format while gz is a compressed format. Most of the time, we an rely on our computer's file explorer to be able to handle these formats, but sometimes, we need to unzip or decompress them on the command line (think remote server). Here are the most common commands.
# Create a .tar format archive
# c is create mode, v is verbose output, f is tar format
tar cvf archive.tar file1 file2 file3 ... filen
# List what is in .tar archive
# t is list mode
tar tvf archive.tar
# To unpack a .tar file
# x is extract mode, v is verbose output, f is tar format
tar xvf archive.tar
# Compress a file or archive
gzip archive.tar # creates archive.tar.gz
# Uncompress
gunzip archive.tar.gz
There a several more options you can explore, but these commands should get you started with compression/archive utilities.