Table of Contents

Process and system management sounds like an intimidating concept, but for the average bash user, there are only a few commands and programs that you will need to learn to get a holistic understanding of how your computer runs.
- What is a process?
- How is a process created?
- How to manage processes with kill, bg, and fg commands
- How to manage processes and monitor system resources with top command
What is a Process?
Without getting super technical, a process is anything on your computer that is owned by a single user and that consumes one of three system resources.
- CPU
- Memory
- I/O (input/output)
While your computer is on and running, the kernel is constantly working. The kernel is constantly monitoring all the processes on your computer and allocating one or more of the three system resources to them in intervals. All the processes are constantly fighting for the resources and will take turns using them. Believe it or not, when you run a program like Google Chrome, the kernel will give it resources for a few seconds and then do a "context switch" where it hands those same resources off to another process for a few seconds. If Google Chrome got 100% of the computer's resources 100% of the time, the computer would become dysfunctional because there are many processes that are running at the kernel level to keep everything in order.
Processes Behind the Scenes
I could list out a bunch of commands here for you, but they will not make any sense unless you understand the sequence that the bash shell (and kernel) takes when a new process is started. When your computer starts up, the kernel will call a process called "init", which on a UNIX-based operating system is usually the script called init located at /sbin/init. This is the systemd init script. This does not make a lot of sense starting out, but once you know how a process starts, you will gain clarity into what goes on behind the scenes on your computer. A process can start another process (usually the terminal starting a new process as a result of a command typed into it) by first creating a copy of itself, and then executing the new command within that copied process. Here is a visual to better explain:
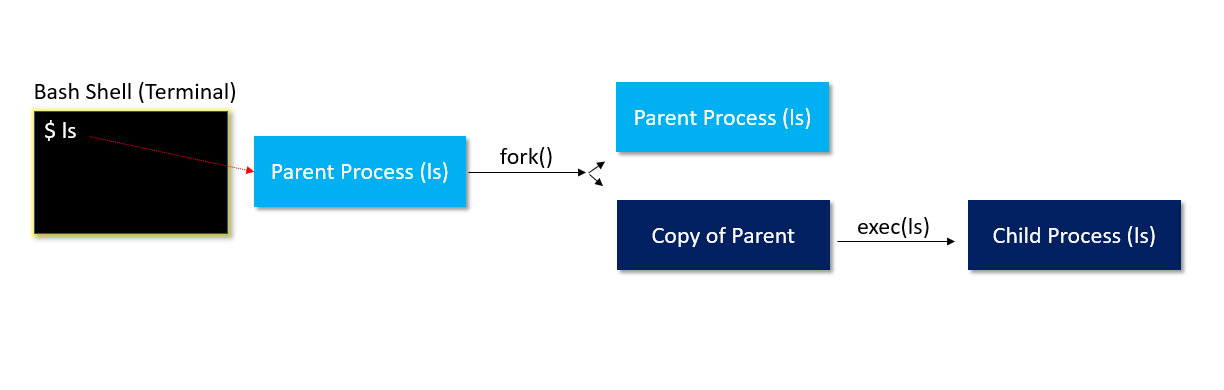
We can also simulate this process in a terminal ourselves using the strace() command. Please note this command is only available on Linux. The equivalent command on Mac is the dtruss command, but it does not work exactly the same.
strace ls
When you run this command, you will see all of the system calls that were made when you ran the ls command. Although ls is considered a "command" in many people's minds, it is really just another process. I have cut out parts of the strace ls output below and highlighted some of the most important parts.
execve("/bin/ls", ["ls"], [/* 69 vars */]) = 0
.... omitted for brevity ....
write(1, "_config.yml awk-example.sh db."..., 107_config.yml awk-example.sh db.json node_modules package.json scaffolds test-permission yarn.lock
) = 107
write(1, "aapl.csv data-file.txt lar"..., 91aapl.csv data-file.txt large-data.csv package-lock.json public source themes
) = 91
close(1) = 0
munmap(0x7f1578100000, 4096) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
If you are truly curious about each of the system calls in the strace command output, here is a great StackOverflow post. If you have ever programmed in the C programming language, you might find a few of these commands familiar.
In the output that I have shown, you can see the execve command starts off the process. This actually does the fork and exec all in one. Later in the command, you will see file and directory names. These represent the output of the ls command that you would see if you just ran ls in the current directory of my machine.
In the end, the output is not important to you as a bash user, but is important in trying to understand how the computer starts and ends processes. What we care more about is how to manage processes. There are only a few commands that we need to look at here because these few commands will take care of essentially anything we would ever need to do relating to processes.
Foreground vs. Background Processes
One of the most important concepts to understand regarding processes is the background vs. the foreground process and how to switch between the two. When you run a process in your bash shell, while that process is running, you will not have access to the terminal. If you want to stop that process, you can always hit the CTRL-C command. But there are multiple processes that are running at any given time, so where are they running? Why don't they prevent you from working in the terminal? The reason is because they are background processes. We can send a process to the background in one of two ways:
- Send it to the background at start time
- Stop it, send it to the background, and start it again
The first method is simple. We can start a process in the background by adding the & character at the end of the command. For example, I can run the sleep command for 20 seconds in the background.
sleep 20 &
The second method is a bit more complicated and requires us to understand the concept of process signals. We can send process signals using the kill command. You can see all the signals by typing kill -l, but here are the most common signals that you might send to a process:
- SIGTERM -
kill(gracefully sends shutdown signal to process) - SIGKILL -
kill -9orkill -s SIGKILL(brute force shutdown) - SIGSTOP -
kill -19orkill -s SIGSTOP(stops running process) - SIGCONT -
kill -18orkill -s SIGCONT(continues stopped process) - SIGINT (CTRL-C) -
kill -2orkill -s SIGINT(interrupt process) - SIGTSTP (CTRL-Z) -
kill -20orkill -s SIGTSTP(stops the running process)
In our case, we want to send the SIGTSTP signal to our running process to throw it in the background and stop it. We will need the process ID to do this. To get that process ID, we can run the ps command (more on this later). In my case, I am running the google-chrome command (will launch a Google Chrome Window) as a sample process that we can work with, and its process ID is 21124 as shown in the ps a output below.
PID TTY STAT TIME COMMAND
1201 tty7 Ssl+ 1:48 /usr/lib/xorg/Xorg -core :0 -seat seat0 -auth /var/run/lightdm/root/:0 -nolis
1204 tty1 Ss+ 0:00 /sbin/agetty -o -p -- \u --noclear tty1 linux
17824 pts/0 Ss 0:00 -bash
18747 pts/1 Ss+ 0:00 /bin/bash
19664 pts/2 Ss+ 0:00 -bash
# This is the Google Chrome Process (this comment was manually added to ps output)
21124 pts/2 SLl 0:03 /opt/google/chrome/chrome
21129 pts/2 S 0:00 cat
21130 pts/2 S 0:00 cat
21133 pts/2 S 0:00 /opt/google/chrome/chrome --type=zygote --enable-crash-reporter=2475ab0f-df4d
21134 pts/2 S 0:00 /opt/google/chrome/nacl_helper
21137 pts/2 S 0:00 /opt/google/chrome/chrome --type=zygote --enable-crash-reporter=2475ab0f-df4d
21164 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=gpu-process --field-trial-handle=39017447716
21169 pts/2 SLl 0:00 /opt/google/chrome/chrome --type=utility --field-trial-handle=390174477165224
21309 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21360 pts/2 Sl 0:01 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21398 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21417 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21711 pts/2 Sl 0:01 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21751 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21852 pts/2 Sl 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=39017447716522
21870 pts/0 R+ 0:00 ps a
I actually have several options here to stop the running Google Chrome process. I could send the SIGTSTP signal (i.e. CTRL-Z), or I could send the SIGSTOP process signal to the process. Either of these will stop the running process and give us our terminal back. I am going to send the SIGSTOP process from a separate terminal window.
kill -s SIGSTOP 21124
# `kill -19 21124` also works
You will notice that when you try to do anything in the Chrome window, it will not work because it is a stopped process. We can now start the process again but this time, we will throw it in the background. To do this, go to the terminal where Google Chrome has stopped and type the command jobs. This will give you that terminal's list of jobs. We want to find the number that Google Chrome is identified by (in my case it is job #1) and run the following command.
bg %1
Google Chrome is now started again and in the background. Let's now stop it again, start it again, and then bring it back to the foreground.
# Stops process
kill -s SIGSTOP 211124
# Starts process
kill -s SIGCONT 211124
# Brings process to foreground
fg %1
ps and top commands (system performance management)
There are two commands that give us output relating to the processes that are currently running on our computer. In 99% of the cases, these commands can be run interchangeably for the same type of data. The difference between the commands is the level of interactivity and therefore the situations you would be likely to use them both in. For example, when you run the top command, you will see a bunch of processes listed out. Not only will this command list processes, but it will also update the status of each process in real time. Since it is interactive, other scripts cannot use it to get information about processes without special configurations (i.e. using "batch" mode). That is where the ps command enters the picture. This command can be run inside bash scripts to obtain necessary information. Since we are not looking to write complex process utilization scripts, we will be primarily focusing on the top command because it is more user-friendly. If you want, you can read the man pages for the ps command to learn the equivalent commands that we talk about (hint: ps ax will print out all your current processes).
Our first priority is to learn the interface of the top command and what we need to look for in the output. This is not just a bash command but an entire program that has extensive capabilities. As a normal bash user you will not use most of the capabilities, but we will look at some useful and common ones.

When first starting the top program, you will see the above output in the header. There will be 5 lines here, and starting from the top line (1) going to the bottom line (5), let's get a better idea of what this means.
- Not all that useful to us--just general info
- Gives a breakout of the different types of tasks running on your computer. These can be running, stopped, sleeping, or zombie. These states are intuitive, except a zombie process, which is just a process that is killed but still showing up in the process table (usually because the parent process has failed to clean it up).
- CPU time statistics including us (user time un-niced), sy (system time), ni (user time niced), id (idle time), and wa (I/O wait time). The hi, si, and st are not important to us. We can find the total user time (time it takes to run the actual code of a program) by adding us + ni. This line will be more helpful to us when we are filtered by a specific process later.
- Actual memory statistics. If you are displaying all your processes and your free memory is low, this could be a red flag that you are running out of RAM.
- Swap memory statistics. Swap memory is only used when real memory is exhausted, so if you start seeing low numbers in the "free" part of real memory and high numbers in the "used" part of swap memory, there could be a performance issue on your computer caused by too little RAM.
Moving down to the actual output of the top command, you may notice that it updates every few seconds. This is useful because we get to see our computer in real time. That said, it would be nice if we could control the interval length. We can do this in one of two ways, which is a good introduction to the topic of "interactive" mode vs. "static" mode. In static mode, we set configuration of the top program on the command line. For example, we might open the top program like so:
top -d 10
This will open the top program and set the interval to 10 seconds. We could also adjust this value by typing the letter d within the top program, and entering the number of seconds for the interval. How did I know this? For one, I read the man pages for the top command, but another way to find this info is by typing the ? within the top program. This will drop you into a help page that gives you hints on how to use the program. From here you will only get information about the "interactive" mode, but generally, this is all you will ever need. Unlike the ps command, we will never need to re-type the top command because all our configurations can be done within the program itself.
The top command is great because it acts as a process management tool and system management tool all in one. Continuing our discussion on process management, we can kill processes within the top program. Just type the letter k followed by the process ID. This will send the default SIGINT kill signal to the process. This does not have any customization (i.e. you cannot send a custom signal), but is a quick way to kill a process without breaking out of top.
We can also filter the top program by process ID, or even user ID. Both of these can be set at the command line when starting the program.
# Only displays the user "zach"'s processes
top -u zach
# Only displays the process 22435
top -p 22435
We can also do these commands interactively within the top program. If we wanted to only show the user zach processes, we type the letter n followed by "zach". If we wanted to display only process ID 22435, we could put a filter on the top output. We do this like so:
- Type the letter
O(uppercase) in interactive mode - Type
PID=22435and press Enter - Check your filters by typing CTRL-o (control + the letter o)
- Clear your filters by typing
=
By default, top gives quite a bit of output, and oftentimes, we will need to scroll through it. You can scroll through the top output using the up, down, left, and right keys. To see what coordinates you are at in the output, just type C. This will give you an output at the top of your screen that says something like scroll coordinates: y = 13/345 (tasks), x = 1/12 (fields).
We can also change what fields are displayed by typing the letter f in interactive mode. When you type this, you will see a bunch of different field options. Before we go into how we can organize our fields, we need to walk through the default fields and what they mean.
- PID - process ID
- USER - user ID that owns the process
- PR - The priority of the process (
rtmeans the priority is set in real time) - NI - The "Nice" value of the process. This is the user space version of priority and is directly related to priority (PR) by the following formula: PR = 20 + NI. For both, the lower the number, the higher the priority. See this post for a more detailed explanation.
- VIRT - All virtual memory used for the process
- RES - subset of VIRT
- SHR - subset of RES
- S - state (S for sleep, R for running, I for idle)
- %CPU - The task's share of elapsed CPU time since last screen update. So if it is 50% and your interval time is 10 seconds, this means that over the last 10 seconds, this process has taken up 50% of all available CPU time.
- %MEM - The same thing as RES, but expressed as a percentage
- TIME+ - The total time the process has used since start time (assuming cumulative mode is on - toggle it with
S) - COMMAND - The command that started the program. Type
cto toggle between the full name and abbreviated name.
Unless you are a system management wizard, some of these default fields are not going to be that useful to you. To change what fields are displayed, you can type f to enter the field manager. When in the field manager, use you up and down arrow keys to highlight a specific field. If the field has a * by it, this means that it is currently showing. You can toggle this on and off using the letter d. To move commands to a different location in the menu, highlight one, press the right arrow key to highlight the entire field, and then press up and down arrow keys until you have placed it where you want it. Finally, press the left arrow key or Enter to place the menu item. You can also change the field which top sorts by highlighting the field and typing the letter s. Press q to quit. Once you have set your favorite configuration, exit out of the field manager and type W to save your settings to the ~/.toprc file.
If you want to display multiple windows in top (usually I do not need this feature), you can enter alternate display mode by typing A. Once in this mode, you can use the a and w keys to move between the four windows (you will see the window update in the top left corner of the page), and type G to rename the current window to whatever you want. The advantage here is the ability to see four windows that are all configured slightly different at the same time.
So we know how to use the top command, but what does it help us with? Generally, you would use this program to check just a few things:
- The summary page - for high level statistics about your computer
- %CPU - check to make sure a single process is not eating all of your CPU resources
- %MEM - check to make sure that a single process is not eating all of your memory resources. Remember, the %MEM represents
RES, which is "resident memory", or in other words, "real memory". VIRT = RES + SWAP, so if a task's VIRT is much higher than RES, this means that it is using SWAP, which means that the computer is running out of space for the process.
The top command is great for getting a high level overview of things in regards to process/system utilization, but we have a few more commands that will give greater insight into how our computer is functioning.
lsof
The lsof command is used for listing out open files on the system. At first glance it does not sound all that interesting, but since UNIX based operating systems store everything as a file, this tool can allow us to see more than just open text files. There are many ways to utilize this tool, but here are a couple that any bash user might find useful at some point.
# List all the files that the user zach has open
lsof -u zach
# List all network connections
lsof -i
# List all processes running on port 22
lsof -i TCP:22
# List all the files that my external hard drive has open
# The +f -- means that we are treating the following as a mount point
lsof +f -- /media/my_hard_drive
free, time
The free command is a concise way of showing your system resources at a given moment. I suggest appending the --mega flag to display the amount of memory in megabytes rather than the default kibibytes.
free --mega
There is also a command called time that will tell you how much CPU time a particular command takes. For example, I could run the following command:
time google-chrome
# Output
# ---------------
# real 0m0.458s
# user 0m0.229s
# sys 0m0.063s
This will run the google-chrome executable (opens a Google Chrome window) and track how much real, user, and system time was used for that executable. Real time is the total elapsed time that it took to run the program. User time is the time it took the code to run, and System time is the time which the kernel was using system resources. The following formula will determine how long the system was waiting for resources.
Wait Time = Real - User - System
It is difficult to know what a reasonable wait time is without benchmarking, but this would be the tool to use for such an analysis.